←
Retour au blog
AI
•
•
Team PixelPilot
•
5 min read
Flux de travail Speech-to-Text
Concevez et exécutez des pipelines speech-to-text : automatisez les transcriptions, imposez des contrôles de qualité et ajoutez des garde‑fous opérationnels pour des déploiements en production fiables.
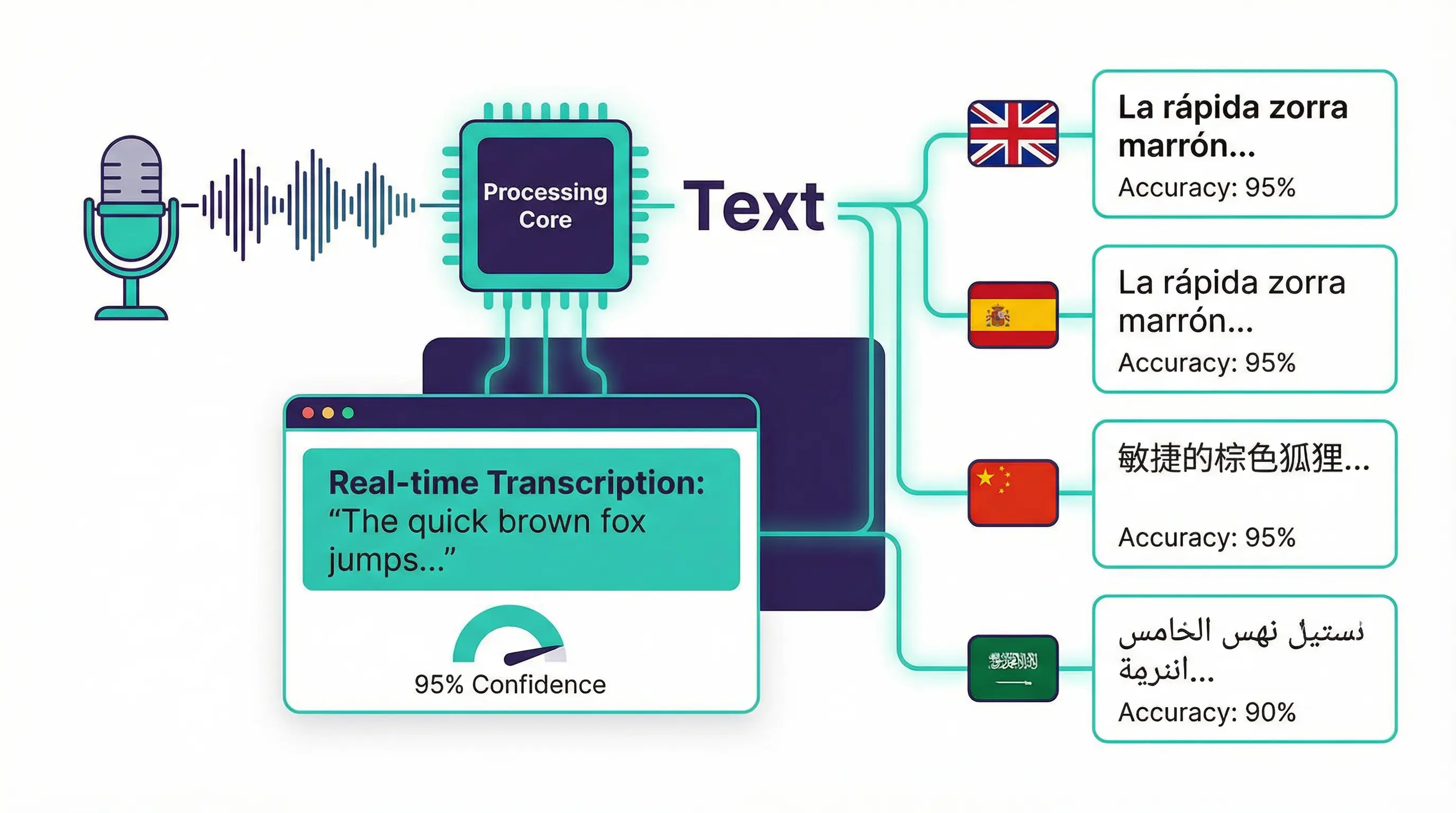
<h2>Introduction</h2> <p>La technologie de reconnaissance vocale transforme la langue parlée en texte écrit. Elle est utilisée dans de nombreux domaines, notamment les services de transcription, les assistants vocaux, le support client et les solutions d’accessibilité. À mesure que les organisations adoptent cette technologie, il devient essentiel de comprendre le fonctionnement des workflows de reconnaissance vocale afin d’améliorer l’efficacité, la précision et l’expérience utilisateur.</p> <h2>Qu’est-ce qu’un workflow de speech-to-text</h2> <p>Un workflow de speech-to-text est un processus étape par étape qui transforme une entrée audio en texte lisible. Il comprend la capture de l’audio, son traitement, la conversion de la parole en texte et la livraison du résultat dans un format exploitable. Ces workflows aident les entreprises à automatiser des tâches telles que les comptes rendus de réunions, les journaux d’appels clients et la génération de contenu.</p> <h2>Capture de l’audio</h2> <p>La première étape d’un workflow de speech-to-text consiste à capturer un audio de haute qualité. Celui-ci peut provenir de microphones, d’appels téléphoniques, d’enregistrements vidéo ou de réunions en ligne. Une bonne qualité sonore est essentielle, car le bruit de fond, les voix qui se chevauchent ou une mauvaise qualité d’enregistrement peuvent réduire la précision de la transcription.</p> <h2>Prétraitement et amélioration</h2> <p>Une fois l’audio capturé, il subit souvent un prétraitement. Cela inclut la suppression du bruit, la normalisation du volume et la séparation des voix lorsque plusieurs personnes parlent. Le prétraitement permet au système de se concentrer sur les mots réellement prononcés et de réduire les erreurs.</p> <h2>Reconnaissance vocale</h2> <p>La reconnaissance vocale constitue le cœur du workflow. Des modèles avancés de machine learning analysent l’audio et convertissent les mots prononcés en texte. Ces modèles peuvent comprendre différents accents, langues et styles de parole. Certains systèmes utilisent également le contexte et des modèles linguistiques pour prédire les mots avec plus de précision, améliorant ainsi la qualité globale de la transcription.</p> <h2>Post-traitement et mise en forme</h2> <p>Après la reconnaissance, le texte brut peut nécessiter un post-traitement. Cela peut inclure la correction de la grammaire, de la ponctuation et la mise en forme pour améliorer la lisibilité. Certains workflows identifient aussi les intervenants, extraient des mots-clés et ajoutent des horodatages pour faciliter la navigation. Le post-traitement garantit que le texte est exploitable pour des rapports, des bases de données ou d’autres applications.</p> <h2>Intégration avec les applications</h2> <p>Les workflows de speech-to-text sont souvent intégrés à d’autres systèmes. Par exemple, les transcriptions d’appels clients peuvent être intégrées à des CRM, les notes de réunion stockées dans des outils collaboratifs, et les sous-titres générés automatiquement pour les vidéos. Cette intégration permet aux organisations de tirer pleinement parti des résultats.</p> <h2>Suivi de la qualité et amélioration</h2> <p>Pour maintenir une précision élevée, les workflows de speech-to-text incluent généralement des mécanismes de suivi et de retour d’information. Cela implique la révision des transcriptions, la mesure de la précision et la mise à jour des modèles ou des dictionnaires pour s’adapter à un vocabulaire spécifique. L’amélioration continue garantit la fiabilité du système dans le temps.</p> <h2>Avantages pour l’entreprise</h2> <p>Les workflows de speech-to-text permettent de gagner du temps et des ressources en automatisant la transcription. Ils améliorent l’accessibilité en fournissant du texte pour le contenu audio et augmentent la productivité en permettant aux employés de se concentrer sur des tâches à plus forte valeur ajoutée. Les organisations obtiennent également de meilleures analyses à partir des données audio, comme les tendances des retours clients ou des discussions de réunion.</p> <h2>Défis et considérations</h2> <p>Les défis liés aux workflows de speech-to-text incluent le bruit de fond, la multiplicité des intervenants, le jargon technique et les préoccupations en matière de confidentialité. Les organisations doivent garantir la sécurité des données, respecter les réglementations et prévoir une révision humaine lorsque cela est nécessaire. Malgré ces défis, les bénéfices d’une transcription automatisée et précise sont considérables.</p> <h2>Conclusion</h2> <p>Les workflows de speech-to-text transforment la manière dont les organisations gèrent l’information orale. De la capture audio à la production d’un texte exploitable, ces workflows rationalisent les processus, améliorent l’accessibilité et fournissent des informations précieuses. À mesure que la technologie progresse, les systèmes de reconnaissance vocale deviendront de plus en plus essentiels aux opérations commerciales modernes.</p> <p>Il est également possible de créer un schéma visuel du workflow illustrant chaque étape, de la capture audio à la sortie finale du texte, ce qui est particulièrement efficace pour les présentations ou les rapports.</p>
Need help with your digital project?
Our team builds websites, mobile apps, e-commerce platforms and runs data-driven marketing campaigns for businesses across the UK.