←
Back to Blog
AI
•
•
Team PixelPilot
•
4 min read
Evaluating LLMs: Metrics That Matter
Define clear, measurable evaluation criteria for LLMs and run focused tests—checking accuracy, calibration, hallucinatio
Introduction
Large Language Models (LLMs) have transformed how businesses automate text generation, customer support, content creation, and decision-making. However, not all LLMs perform equally. Evaluating their effectiveness requires systematic measurement across multiple dimensions: accuracy, relevance, efficiency, safety, and user experience.
Selecting the right model without proper evaluation can lead to bias, misinformation, and wasted resources. Understanding which metrics matter helps organizations align LLM capabilities with business goals.
Core Metrics for Evaluating LLMs
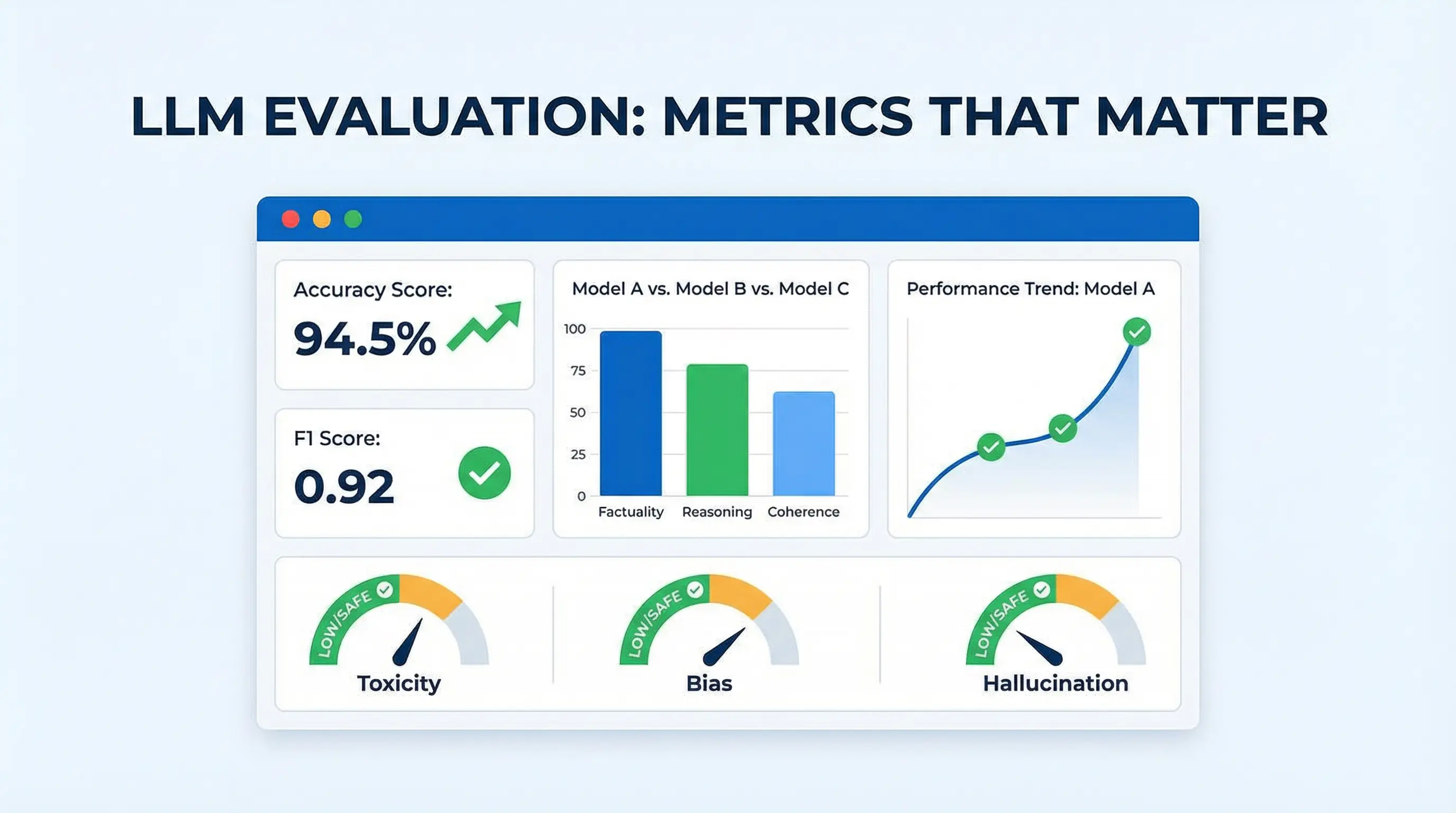
1. Accuracy and Correctness
Definition: How well the model’s output matches factual, verified information
Methods: Compare outputs against ground truth datasets, human-labeled references, or structured knowledge bases
Importance: Critical for applications like legal documents, medical advice, or financial analysis
Example: An LLM summarizing a contract should preserve key obligations without introducing errors.
2. Relevance and Contextual Understanding
Definition: The model’s ability to generate responses aligned with user intent
Evaluation: Use human judgment or automated metrics like ROUGE, BLEU, or semantic similarity scores
Importance: Ensures the output is meaningful and actionable
Example: In a customer support chatbot, relevance measures whether the response addresses the user’s question accurately.
3. Coherence and Fluency
Definition: How logically and grammatically well-formed the output is
Evaluation: Human raters score fluency, or automated metrics check for grammatical correctness and sentence structure
Importance: Affects readability and user trust in the model
Example: Summaries, blog posts, or reports generated by the LLM should read naturally without awkward phrasing.
4. Robustness and Generalization
Definition: The model’s ability to handle unexpected or edge-case inputs
Evaluation: Test with adversarial prompts, incomplete sentences, or rare scenarios
Importance: Ensures consistent performance across diverse use cases
Example: A question-answering model should perform well even with typos, ambiguous queries, or multi-part questions.
5. Bias and Fairness
Definition: The degree to which outputs are neutral, inclusive, and free from unfair stereotypes
Evaluation: Audit model outputs across demographics, industries, or sensitive topics
Importance: Critical for responsible AI deployment and compliance
Example: Avoid generating biased hiring recommendations or politically skewed content.
6. Safety and Toxicity
Definition: Ensuring outputs do not contain harmful, offensive, or unsafe content
Evaluation: Use automated toxicity detection tools (like Perspective API) and human review
Importance: Essential for public-facing applications, chatbots, and user-generated content moderation
7. Latency and Efficiency
Definition: How quickly the model generates responses and the computational cost involved
Evaluation: Measure inference time, throughput, and resource consumption (CPU/GPU usage)
Importance: Impacts user experience, operational cost, and scalability
Example: Customer support chatbots require sub-second response times to maintain engagement.
8. Hallucinations and Factuality
Definition: Occurrence of incorrect or fabricated information in the output
Evaluation: Cross-check outputs with knowledge sources or employ automated factuality detection
Importance: High stakes in healthcare, finance, and legal applications
Quantitative vs. Qualitative Evaluation
Quantitative metrics: BLEU, ROUGE, METEOR, perplexity, token usage, latency
Qualitative evaluation: Human review of relevance, coherence, safety, and alignment with business goals
Best practice: Combine both approaches for holistic assessment
Domain-Specific Considerations
Customer Support: Prioritize relevance, latency, safety, and coverage of FAQs
Content Generation: Focus on coherence, fluency, creativity, and factuality
Decision Support: Emphasize accuracy, robustness, bias, and explainability
Continuous Evaluation and Monitoring
LLM performance can drift over time as data distributions and user behavior change
Implement continuous monitoring pipelines to track key metrics post-deployment
Establish alert thresholds for anomalies, such as spikes in toxic outputs or hallucinations
Best Practices for Organizations
Define success criteria upfront aligned with business objectives
Use benchmark datasets relevant to the intended domain
Include diverse evaluation teams to capture multiple perspectives
Automate metric collection where possible but combine with human judgment
Iterate and retrain models based on performance gaps
Business Benefits
Properly evaluating LLMs ensures:
Reliable and trustworthy outputs for critical tasks
Better user experience by producing relevant and coherent content
Reduced risk of bias, toxicity, or regulatory violations
Optimized costs by selecting efficient models for deployment
Challenges
Metrics alone cannot capture all aspects of usability and value
Some qualitative aspects like creativity or novelty are hard to quantify
Monitoring post-deployment requires continuous investment in tooling and human review
Balancing accuracy, latency, and safety can require trade-offs
Conclusion
Evaluating LLMs goes far beyond simple accuracy. Organizations must consider relevance, coherence, fairness, safety, latency, and factuality to make informed deployment decisions. By defining the right metrics, combining quantitative and qualitative approaches, and continuously monitoring performance, teams can maximize business value, reduce risk, and maintain trust in AI-driven systems.
Need help with your digital project?
Our team builds websites, mobile apps, e-commerce platforms and runs data-driven marketing campaigns for businesses across the UK.