←
Back to Blog
AI
•
•
Team PixelPilot
•
3 min read
Data Labeling and Quality
Implement labeling pipelines, QA gates, and scheduled review cycles to raise dataset accuracy and produce more reliable
Introduction
High-quality data is the backbone of machine learning (ML) and artificial intelligence (AI). Raw data alone is rarely sufficient; it must be accurately labeled and curated to train models that perform reliably.
Data labeling is the process of annotating data—text, images, audio, or video—so machines can learn patterns and make predictions. Data quality ensures that labels are accurate, consistent, and representative of real-world scenarios. Together, they determine the accuracy, fairness, and trustworthiness of AI systems.
Understanding Data Labeling
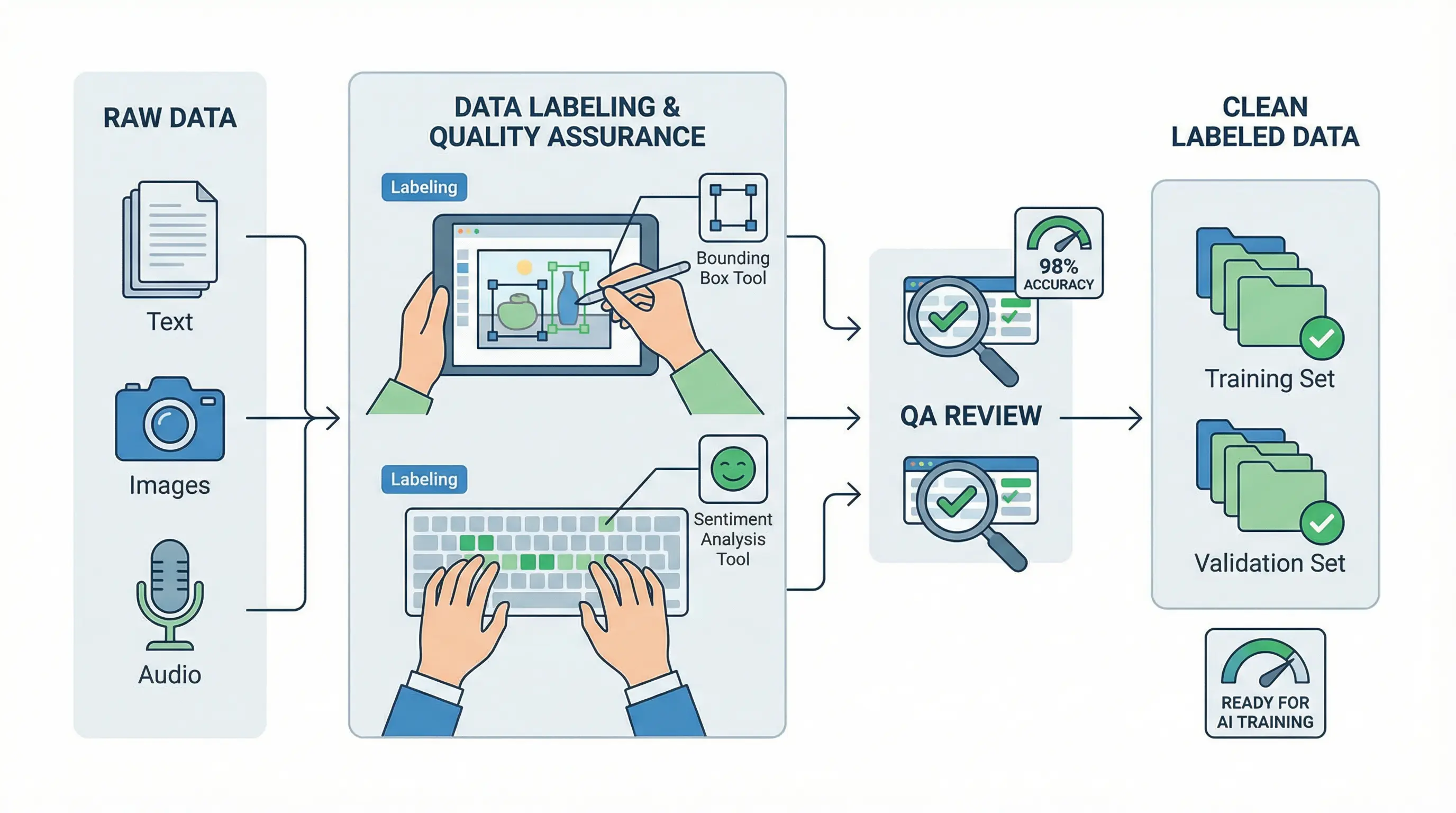
What is Data Labeling?
Assigning tags, categories, or metadata to raw data
Provides the “ground truth” for supervised machine learning
Examples:
Text: Sentiment classification (positive, negative, neutral)
Images: Bounding boxes for objects or facial landmarks
Audio: Transcribing speech or labeling emotions
Video: Tracking movements or actions
Types of Data Labeling
Manual Labeling – Human annotators review and tag data
Pros: High accuracy and nuanced understanding
Cons: Time-consuming and costly
Semi-Automated Labeling – AI-assisted labeling reviewed by humans
Pros: Speeds up labeling while maintaining quality
Cons: Requires careful human validation
Automated Labeling – Fully automated using AI or rule-based systems
Pros: Fast and scalable
Cons: Risk of errors and bias; may require human verification
Ensuring Data Quality
High-quality labeled data is consistent, accurate, and unbiased. Key dimensions include:
Accuracy
Labels must reflect reality and match defined guidelines
Errors in labeling can propagate to biased or incorrect model predictions
Consistency
All annotators must apply the same rules and criteria
Use annotation guidelines, training, and review processes
Completeness
Ensure the dataset covers all relevant scenarios
Avoid gaps that lead to poor model performance on unseen data
Representativeness
Labels should reflect the diversity of real-world conditions
Reduces bias and improves generalization
Best Practices for Data Labeling
1. Define Clear Guidelines
Provide examples, edge cases, and instructions for annotators
Include rules for handling ambiguous or incomplete data
2. Use Multi-Level Review
Implement peer review or consensus labeling
Use multiple annotators per data point for higher confidence
3. Leverage Tools and Platforms
Annotation tools: Label Studio, Supervisely, Scale AI, Amazon SageMaker Ground Truth
Features: Bounding boxes, segmentation masks, transcription, tagging, and quality checks
4. Automate Where Possible
Pre-labeling using models can accelerate human review
Use active learning to prioritize uncertain or high-value samples
5. Monitor Metrics and Feedback
Track label accuracy, inter-annotator agreement, and error rates
Continuously refine guidelines and retrain annotators
Challenges in Data Labeling
Volume: Large datasets require scalable labeling solutions
Complexity: Ambiguous or subjective data may lead to inconsistent labels
Bias: Annotator bias can lead to skewed datasets
Cost: Manual labeling can be expensive and time-consuming
Data Privacy: Sensitive data requires careful handling and compliance
Data Quality in Machine Learning
Impact on Models
Poor-quality labels lead to low model accuracy, unexpected predictions, and bias
High-quality data improves generalization, fairness, and reliability
Quality Assurance Techniques
Spot checks and audits: Randomly verify annotated samples
Inter-annotator agreement: Measure how often annotators agree on labels
Validation datasets: Hold back high-quality labeled data for testing model performance
Feedback loops: Use model errors to refine labeling and improve future datasets
Business Benefits
Faster model training and deployment with reliable data
Reduced risk of errors or bias in AI systems
Cost efficiency through fewer iterations and retraining cycles
Better user experiences with accurate, context-aware AI applications
Regulatory compliance by ensuring traceable and auditable data pipelines
Conclusion
Data labeling and quality are cornerstones of successful AI and ML initiatives. Accurate, consistent, and representative labels ensure that models learn correctly, make fair predictions, and perform reliably in production.
Organizations that invest in structured labeling workflows, quality monitoring, and continuous improvement can unlock faster innovation, higher model performance, and safer, more trustworthy AI systems.
Need help with your digital project?
Our team builds websites, mobile apps, e-commerce platforms and runs data-driven marketing campaigns for businesses across the UK.